
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- bounded context
- IOC
- redis
- jvm
- JWT
- 서명
- Java
- Generic
- junit5
- AOP
- PSA
- Exception
- JSON
- reflection
- bytecode
- SOA
- Spring Data Redis
- Rest
- rest api
- OOP
- *
- ddd
- mockito
- MSA
- di
- Transaction
- spring
- Today
- Total
개발자일기
카프카 개념과 특징 본문
카프카란
분산 메세지징 시스템, 데이터 파이프라인 라인을 만들때 주로 사용되는 플랫폼
카프카 특징(장점)
영속성(Persistence)
- 메세지를 파일시스템(디스크)에 저장
- Kafka는 기존 메시징 시스템과는 달리 메시지를 메모리 대신 파일 시스템에 쌓아두고 관리함
- 장애시에 오프셋을 이용해 이전의 메세지 참조 가능
- 디스크 IO는 성능 저하를 유발할수 있지만, 메세지를 디스크에 순차적으로 저장 및 최적화를 통해 해결함(그림참조)

- 메시지는 하드디스크로 부터 순차적으로 읽음
- 하드디스크의 랜덤 읽기 성능에 대한 단점을 보완, 동시에 OS 페이지 캐시를 효과적으로 활용할 수 있다.
- 하드디스크의 순차적 읽기 성능은 메모리에 대한 랜덤 읽기 성능보다 뛰어남
- 메모리의 순차적 읽기 성능보다 7배 정도 느리다. (물론 하드디스크의 랜덤 읽기 성능은 메모리의 랜덤 읽기 성능보다 10만배나 느리다.)
고가용성 확장성
- 클러스터로 동작하여 fail over처리
- scale out(브로커 확장 가능)
높은 성능(처리량에 중점)
- 브로커 scale out으로 메세지 처리량 향상
- AMQP 프로토콜이나 JMS API를 사용하지 않고 단순한 메시지 헤더를 지닌 TCP기반의 프로토콜을 사용하여 프로토콜에 의한 오버헤드를 감소
- 메세지 배치 가능 (그림 참조)
- 그림을 보면 batch size에 따른 producer/consumer 성능 차이를 확인 할수 있다.


다른 메세지 시스템과의 차이
| Kafka | SQS | RabbitMq | |
| fetch방식 | pull | pull | push |
| 순서보장 | 지원 | 일부지원(fifo queue) | 미지원 |
| 배치 | 지원 | 지원 | 지원 |
kafka vs rabbitMq
kafka
- 대용량의 streaming, 파이라인등을 이용 시 적합
- 이벤트 스토어, 히스토리 같은 순서 보장시 사용
rabbitMq
- 브로커가 다양한 라우팅 제공
- legacy한 프로토콜 STOMP, MQTT, AMQP 지원 해야할때 사용
- 어드민 및 UI 편리
https://tanzu.vmware.com/developer/blog/understanding-the-differences-between-rabbitmq-vs-kafka/
카프카 인프라 아키텍쳐
주키퍼, 브로커들로 구성된다.
주키퍼
- 분산 어플리케이션(브로커)을 관리를 위한 코디네이션(관리) 시스템
- Cluster를 이루는 각 Kafka Broker의 동작 상태를 파악하고 상태 정보를 Producer 및 Consumer에게 전달
- 브로커들의 메타 데이터를 유지 및 관리
- 지노드 :key, value값 저장소, 브커커들은 서로 데이터를 주고 받음
- 카프카 클러스터의 컨트롤러, 브로커 정보, 토픽(offset)정보 을 저장
브로커
- 각 카프카 어플리케이션 서버
- 컨트롤러: 카프카 브로커 중 하나, 파티션 리더를 선출 역할을 함
카프카 데이터 모델
토픽
구독 대상, 메세지를 구분하기 위한 네임스페이스 개념
파티션
토픽내에서 물리적/논리적으로 분할된 그룹

파티션 분산
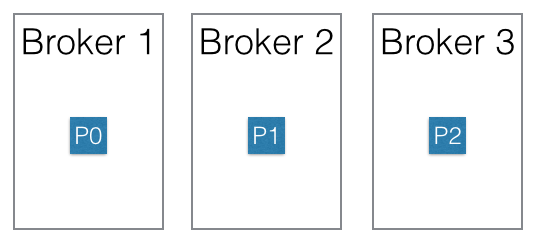
파티션은 여러 브로커에 균등히 분배 된다.
파티션 복제

고가용성을 위해 파티션을 복제 할수있다.
현재 factor이 3으로 설정됨, 붉은색 1개의 리더, 파란색 2개 follower
파티션 수
파티션의 수에 따라 분산(병렬)처리가 가능하다.
하지만 파티션 수를 무조건 늘리면 단점이 있다.
- 파일 핸들러의 낭비
- 장애 복구 시간 증가.
적절한 값으로 유지하는게 좋다.
그리고 파티션을 늘리는것은 가능하나 줄 이는 것은 불가능 하다.
오프셋 메세지 순서

파티션 마다 메세지 저장 위치를 오프셋이라고 한다.
파티션 내에서 오프셋을 이용해서 메세지 순서를 보장
컨슈머가 오프셋 순서대로 메세지를 가져감
카프카 프로듀서
파티션 선정 방식
- 파티션 키로 내부의 hash 알고리즘을 이용하여 파티션 지정
- 직접 파티션을 지정할수도 있음
한번 파티션이 지정되면 같은 키 는 해당 파티션으로 메세지가 전달된다.
ack 모드
ack 모드 가 높을수록 속도는 느리지만, 손실이 없음
- acks =0, 서버로부터 어떤 ack도 기다리지 않음
- acks =1, 리더에게만 데이터 기록됬지만 보장
- acks = all, -1, 리더 + 팔로워로 부터 모든 ack
카프카 컨슈머
컨슈머
- 토픽 구독(파티션)을 구독한다.
- 어느 파티션을 구독 할지 지정할수 있고, 자동으로 리밸런싱 하여 분배하게 된다.
- A,B컨슈머가 1개의 파티션을 구독하다가, A가 사라지면 B가 2개다 구독하게된다.
- 파티션은 하나의 컨슈머(컨슈머그룹내)만 허용한다.(컨슈머 : 파티션 == 1: N)
- 컨슈머 > 파티션수 이면 컨슈머는 놀게 된다.
컨슈머 그룹
- 컨슈머 그룹은 하나의 토픽(파티션)에서 여러 컨슈머 그룹이 동시에 접속해서 가져올수 있다.
- 보통 일반 queue들은 하나의 컨슈머가 sub하면 다른 컨슈머는 메세지를 가져올수 없다.
- 하지만 카프카는 컨슈머 그룹이 각각 자신이 읽은 오프셋을 관리한다.
- ex) 주문 토픽의 메세지를 중계 그룹, 검색 그룹에서 각각 가지고 갈수 있다.

커밋과 오프셋
컨슈머는 poll을 하여 읽지 않은 메세지를 가져온다. 어디까지 읽었는지 알기 때문이다.
컨슈머 그룹의 컨슈머들은 각각의 파티션에 자신이 가져가 메세지의 오프셋을 기록한다. 이런 행위를 커밋이라고 한다.
커밋 방식
- 자동 커밋
- 수동 커밋
오프셋 리셋
컨슈머는 저장된 오프셋이 없으면 오프셋을 reset(설정)한다.
- earliest: 가장 초기의 오프셋값으로 설정
- latest: 가장 마지막 오프셋값 설정
- none: 이전 오프셋값 없으면 에러 발생
리밸런싱
https://always-kimkim.tistory.com/entry/kafka101-consumer-rebalance 참조
[Kafka 101] 컨슈머 그룹 리밸런싱 (Consumer Group Rebalance)
들어가며 카프카를 운영하다 보면 여러 상황을 맞이하게 됩니다. 특히 성능 향상을 위해 특정 토픽의 파티션 수를 증가하거나 혹은 컨슈머 그룹에 컨슈머를 추가하는 경우가 있습니다. 하지만
always-kimkim.tistory.com
- 컨슈머 그룹의 멤버 변화 : 새로운 컨슈머 추가 및 기존 커슈머 장애 및 종료
- 새로운 파티션 추가 및 re-assign 등
heartbeat.interval.ms: 그룹 코디네이터에게 얼마나 자주 kafka consumer poll() 메소드로 heartbeat 를 보낼 것인지 조정한다.일반적으로 session.timeout.ms 보다 1/3 정도로 설정한다.
기타
카프카 스트림즈
카프카의 강력한 성능으로 인해 실시간으로 연속된 메세지인 스트림을 처리하기 위해 개발된 클라이언트 라이브러리.


카프카 커넥터
Kafka Connect는 데이터를 스트리밍하기위한 프레임 워크
카프카와 데이터 스토리지 사이에 존재.
관계형 데이터베이스 또는 HDFS와 같이 일반적으로 사용되는 시스템에서 데이터를 스트리밍하는 데 사용할 수있는 여러 내장 커넥터 와 함께 제공됩니다 .

'개발' 카테고리의 다른 글
| Lettuce Redis Cluster 적용 (0) | 2021.11.21 |
|---|---|
| 가변보다 불변객체 (0) | 2020.05.25 |
| 생성자 대신 정적 팩토리 메소드를 고려하자 (0) | 2020.05.22 |
| 객체지향 생활 체조 원칙 3: 모든 원시값과 문자열을 포장한다. (0) | 2020.05.22 |
| 객체 지향 생활 체조 원칙 규칙 8 : 일급 컬렉션 (0) | 2020.05.17 |